Building a CDC Pipeline by Using Supabase, Upstash Kafka and TinyBird

Change Data Capture (CDC) is a technique used in databases and data management systems to identify and capture changes made to data.
The primary goal of the CDC is to recognize and track alterations in data so that only the modified information needs to be processed, transmitted, or stored rather than dealing with the entire dataset. This way, we can stream the necessary data with other targets in real-time without overloading our database.
In this blog post, we are going to create a CDC pipeline by using Supabase as the source PostgreSQL database, TinyBird as the target and Upstash Kafka as the connection between the source and the target.
CDC Pipeline
The design of the CDC pipeline in this example is going to be simple. We are going to use Supabase PostgreSQL as the source of this pipeline.
The changes in the specific PostgreSQL tables will be streamed through Serverless Kafka. To connect Supabase to Upstash Kafka, we are going to leverage the Debezium PostgreSQL Source Connector provided by Upstash.
Once we get the updates from the Supabase database to the Kafka topic, we can connect our Kafka topic to TinyBird to create APIs that pull data from the updates in PostgreSQL table.
Here is the simple flow of the CDC pipeline:

Creating this pipeline is going to be easier than drawing it!
Let’s get started from the source and move towards the target.
Supabase Setup
Supabase is an open-source alternative to Firebase. It provides the following services:
- Authentication
- Database (PostgreSQL)
- Storage
- Edge Functions
- Real-time Event Streaming through Websockets
If you are looking for further information, please check Supabase website.
You can also check my previous blog post, which explains how to stream events from Supabase.
Let’s sign in and create a Supabase project if you haven’t yet.
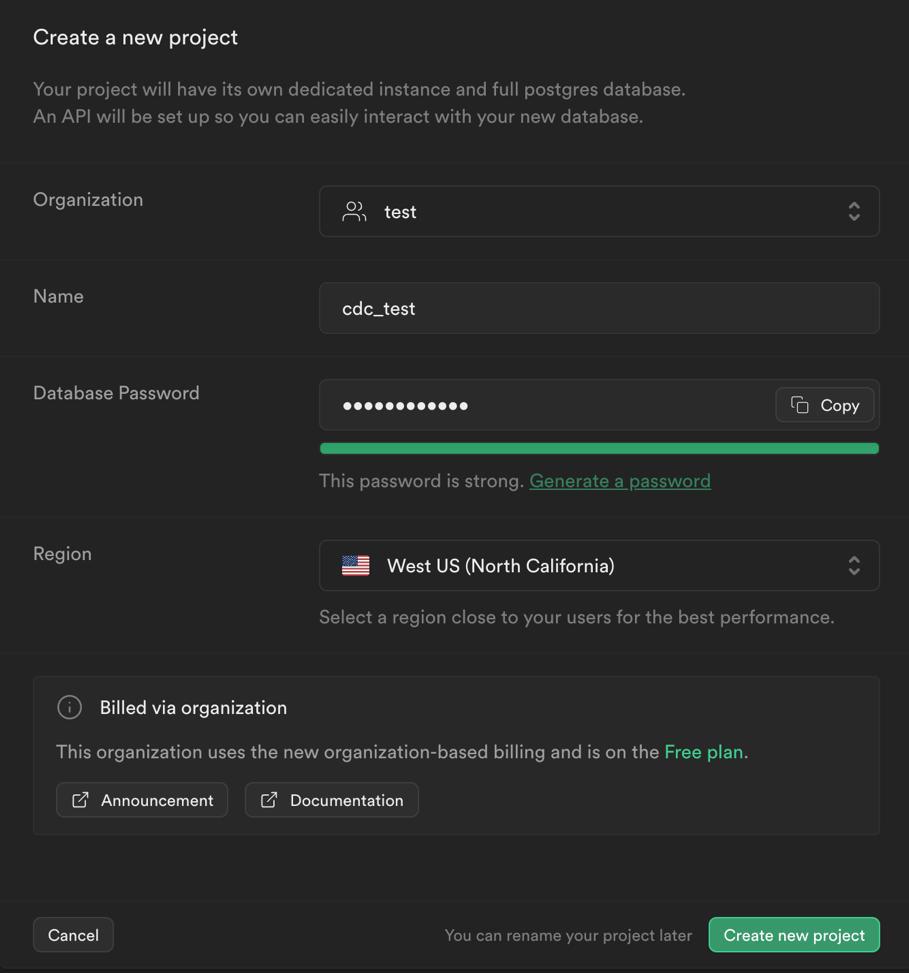
Don’t forget the password you have chosen here. We will need it later to connect to the Kafka cluster.
Now, we can create a new table from Table Editor tab on the right.
In the Table Editor, click New Table.
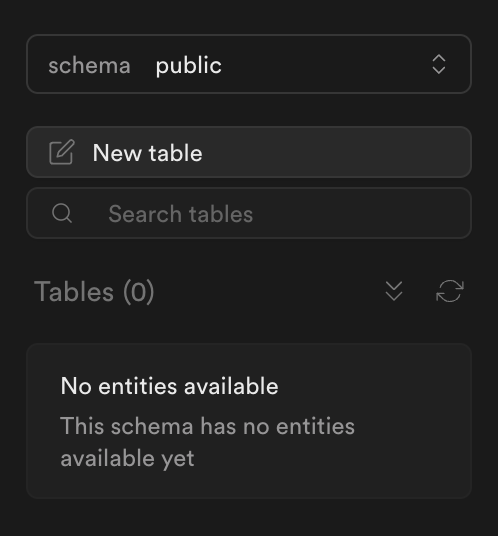
Since this is a demo project showing how to create a CDC pipeline, we will create just one table with a simple structure.
The table will have three columns: name, city and country.
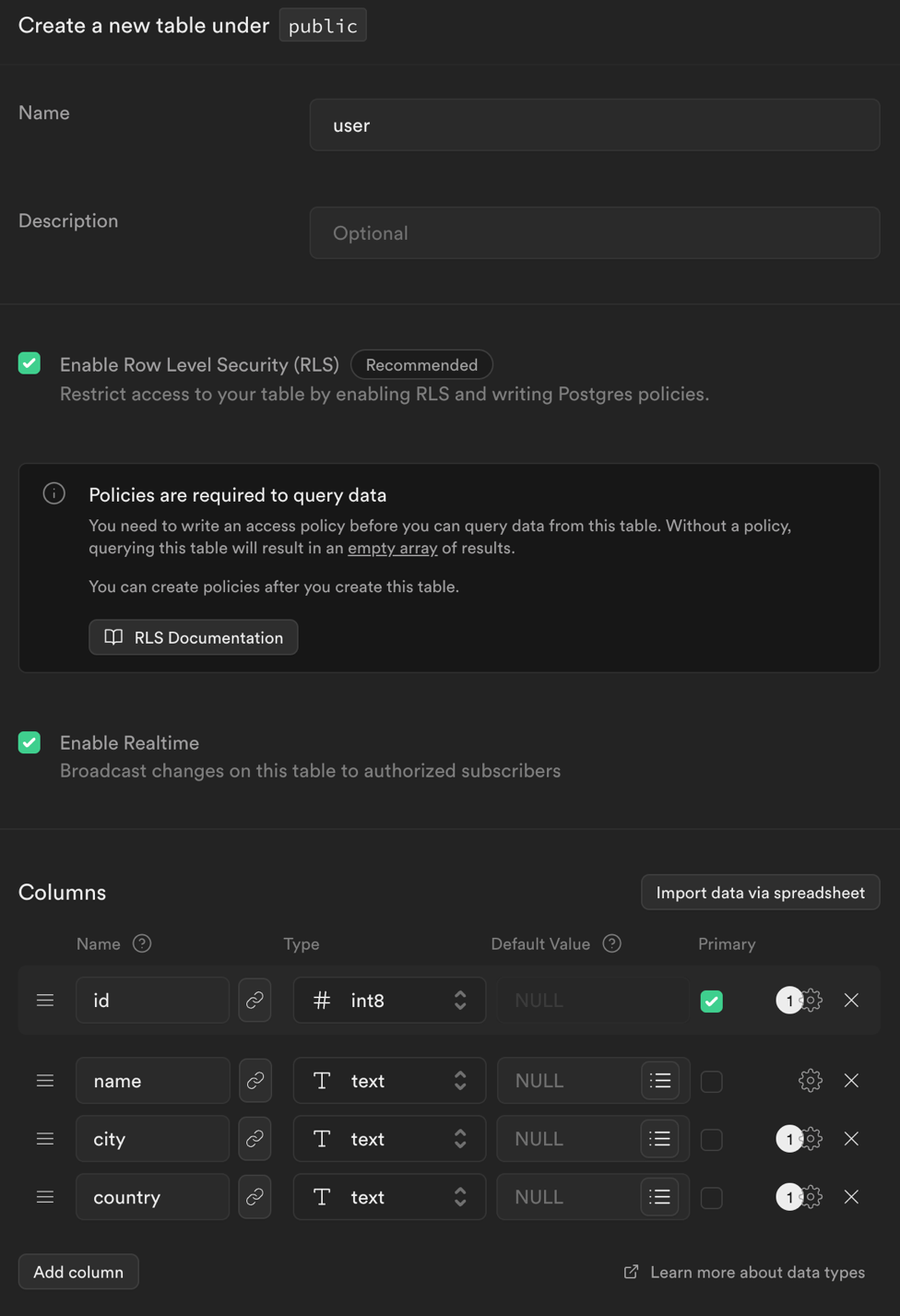
We need to enable real-time while creating the table.
Click Save and the table is ready!
We can add rows to the table by clicking Insert button in Table Editor.
Let’s write some random data as the first row.
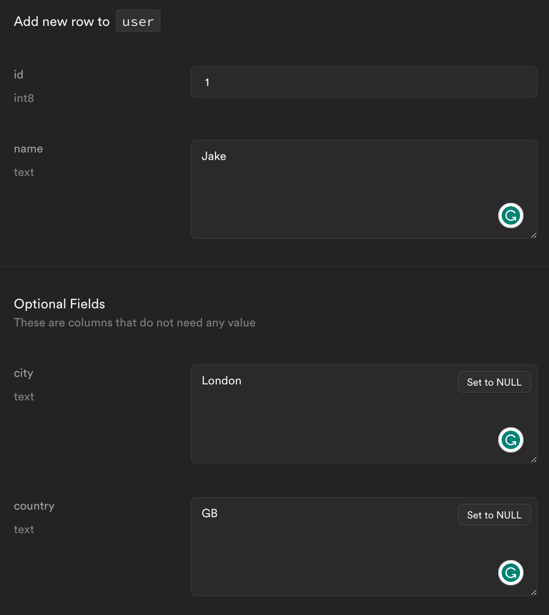
Our PostgreSQL database is up and ready.
Upstash Kafka Setup
In this stage, we will create the Upstash Kafka cluster and Debezium PostgreSQL Source Connector.
First, let’s go to the Upstash console and create a Kafka cluster under Kafka tab.
We can create the Kafka cluster by following the Kafka docs.
Once we have the cluster, we can create a connector under the Connectors tab in the cluster.
Upstash provides a bunch of connector types. The one we need is a Debezium Source PostgreSQL Connector.
To complete the configuration step for the new connector, revisit our Supabase project and open the database settings from the settings tab on the left. We will utilize the host, port, user, project password, and database name in the configuration of the Kafka connector.

We can choose any desired names for both the connector and server.
For this demo, we will select JsonConverter as the key and value converter.
In the next step, we must add the following settings to the properties.
"plugin.name": "pgoutput",
"publication.autocreate.mode": "filtered"
The configuration should look like this:
{
"name": "cdc",
"properties": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "db.hmabqqpnhltyboywhnvp.supabase.co",
"database.port": "5432",
"database.user": "postgres",
"database.password": "********",
"database.dbname": "postgres",
"database.server.name": "cdc",
"schema.include.list": "public",
"plugin.name": "pgoutput",
"publication.autocreate.mode": "filtered",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": true,
"value.converter.schemas.enable": true
}
}
We can see that a Kafka topic in <server_name><schema_name><table_name> format is created automatically.
Testing Supabase – Kafka Connection
To test our Kafka connector that connects Supabase to Upstash Kafka, let’s open the topic from the Upstash Console. Select Messages tab. We will monitor the incoming messages here.
Now, in another tab, we will open Supabase Table Editor. Select the table we have created.
Let’s insert a new row as we did before in this blog.
After inserting the new row, we can go back to the Upstash Console and check whether the Kafka topic received the database change.
We should see a big JSON data containing the row's new value. Since the row is new, we will see the previous value as null.

Tinybird Setup
Tinybird is a serverless real-time data analytics platform for developers. Key features of Tinybird are as follows:
- Data ingestion at any scale
- Transform using SQL
- Publishing low-latency, high-concurrency HTTP APIs
In this blog post, Tinybird will be the target in the CDC pipeline. We will stream the data from Upstash Kafka to Tinybird to transform and publish HTTP APIs.
Let’s first login to Tinybird.
We should select a region as the next step. Selecting the region closer to the Upstash Kafka cluster would be better.

Once we create the workspace, we will click the Add Data button and select Kafka in the following pop-up.
We will use Upstash Kafka cluster credentials in Tinybird to create a connection.
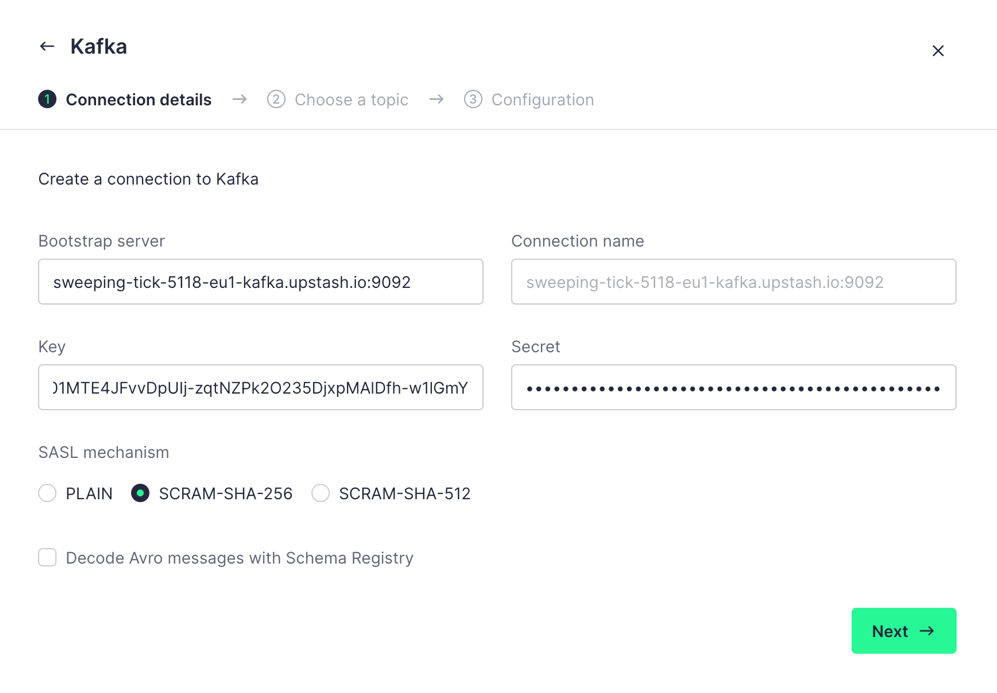
Go back to the Upstash Kafka cluster and copy the fields to Tinybird as follows:
- Boostrap Server = Kafka Endpoint
- Connection Name = Kafka Endpoint
- Key = Kafka Username
- Secret = Kafka Password
Lastly, select SCRAM-SHA-256 as SASL mechanism and click next.
In the next screen, we should select the topic connected to the Supabase in the previous section.
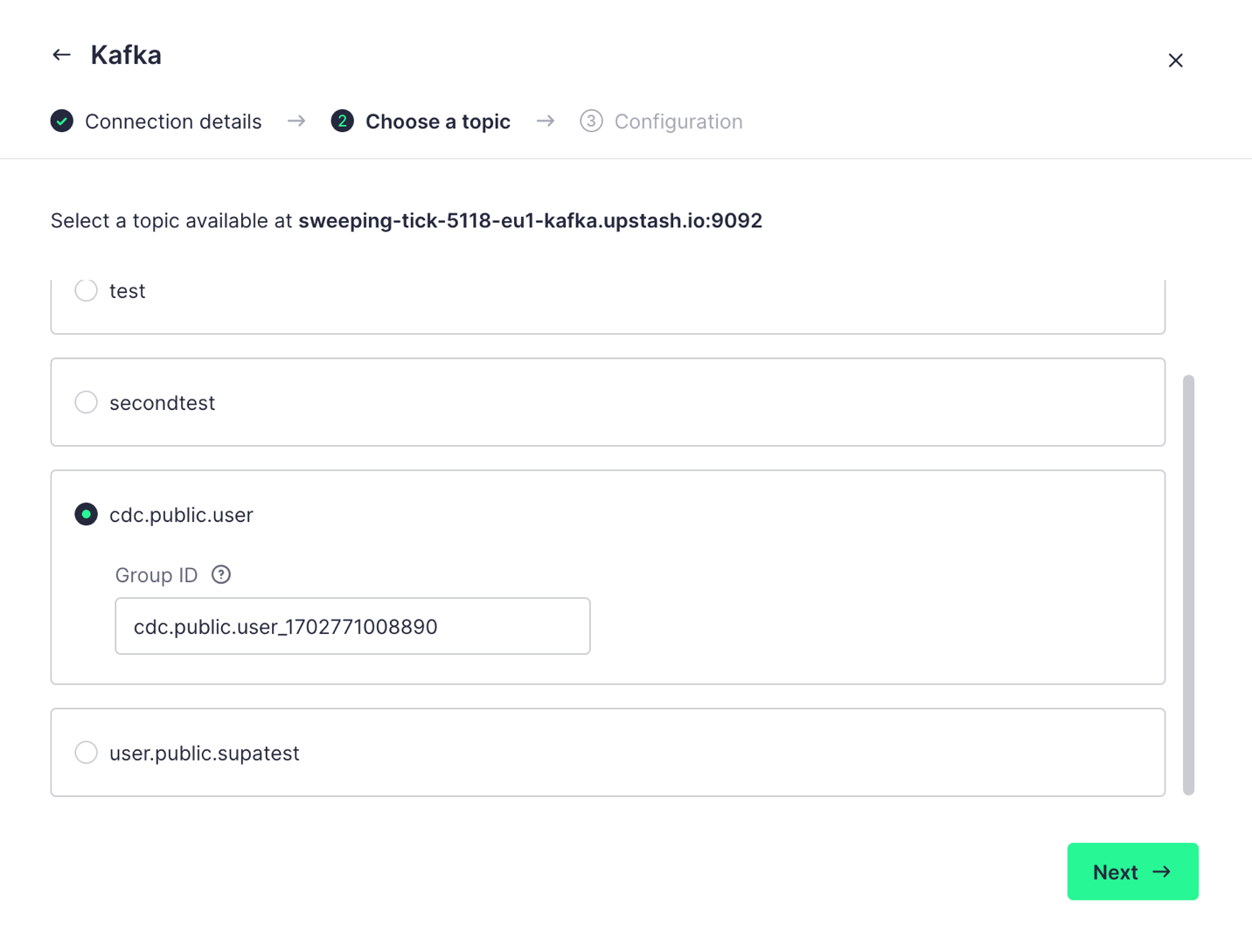
In the next step, we will select Latest and click Next.

In the last step, we can see the data retrieved from the Kafka topic in a table format.
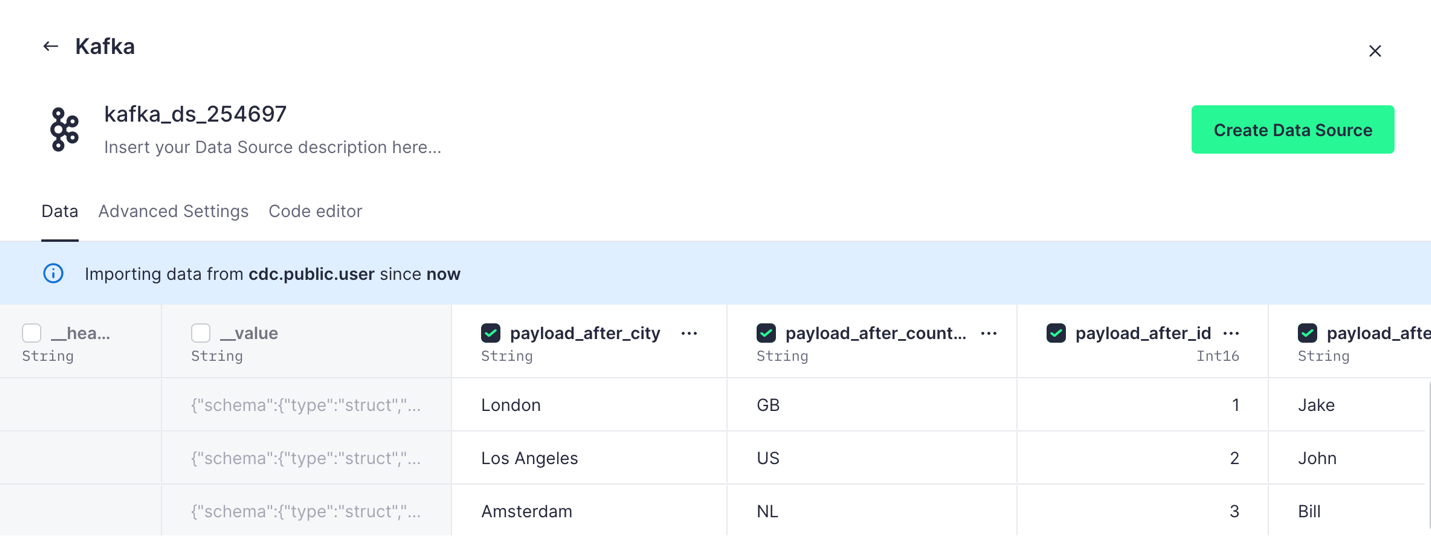
You can select the columns you want to retrieve from the Kafka topic to Tinybird.
Finally, we can create the data source.
Now, the data is being ingested into Tinybird from Upstash Kafka. We can click Create Pipe and run an SQL query on the data that Tinybird fetches from the Upstash Kafka cluster.
In our use case, we want to simplify the data and use only 3 columns: name, city and country. To do that, we will run the following query in the data pipe:
SELECT payload_after_name as name, payload_after_city as city, payload_after_country as country FROM kafka_ds_254697SELECT payload_after_name as name, payload_after_city as city, payload_after_country as country FROM kafka_ds_254697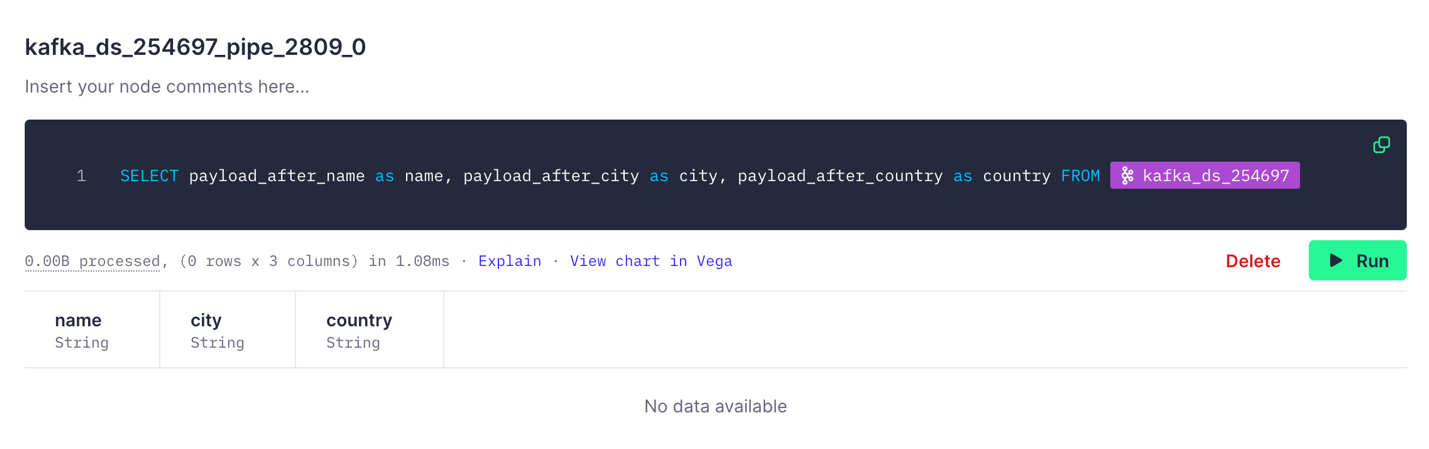
At the end, we can create an API Endpoint from this pipe by clicking on Create API Endpoint. You can view and use the API in Swagger by clicking the Open in Swagger button.
That’s it!
We now have an HTTP endpoint that gives the data updates in the Supabase.
Testing the Pipeline
Now let’s run an end-to-end test on our CDC pipeline.
Since the HTTP endpoint that Tinybird created returns the data updates in the Supabase table, we first need to add new data to the table.
We can add an example data on the Supabase table editor.
Id: 4
Name: Karen
City: Paris
Country: FR
After inserting this row, we can go back to Swagger UI and call the HTTP endpoint with GET method.
We should see the response below:
{
"meta": [
{
"name": "name",
"type": "String"
},
{
"name": "city",
"type": "String"
},
{
"name": "country",
"type": "String"
}
],
"data": [
{
"name": "Karen",
"city": "Paris",
"country": "FR"
}
],
"rows": 1,
"statistics": {
"elapsed": 0.089911899,
"rows_read": 1,
"bytes_read": 39
}
}{
"meta": [
{
"name": "name",
"type": "String"
},
{
"name": "city",
"type": "String"
},
{
"name": "country",
"type": "String"
}
],
"data": [
{
"name": "Karen",
"city": "Paris",
"country": "FR"
}
],
"rows": 1,
"statistics": {
"elapsed": 0.089911899,
"rows_read": 1,
"bytes_read": 39
}
}Conclusion
In this blog post, we created a CDC pipeline that ingests a PostgreSQL table's updates into Tinybird through Upstash Kafka.
All of this CDC pipeline's components have been built using serverless tools. We didn’t need to deal with any infrastructure creation by ourselves.
You can easily create much more complex projects with these tools.
Let the serverless world do the work for you!