Semantic Search Engine for Docs Using Upstash

Welcome to a new blog post. In this blog, we will create a semantic search engine applicable to any repository on Github using Upstash Vector.
What is Semantic Search?
Semantic search basically means "searching with meaning". In a simple search, we take the user input and look for exact matches in the database. However, when developing a search engine, our goal is to achieve more nuanced results. For instance, if a user searches for "soccer," the engine might also return results for "football," recognizing these as related terms.
Semantic search helps us with this issue. In semantic search, search domain is kept in the vector database as embeddings which are multi-dimensional vectors that are created considering the relations of words. In this approach, search queries are turned into embeddings too. So, result "soccer" becomes possible when the query is "football".
Project Description
The project will be implemented on Next.js using Javascript. Since this is a engine tutorial, UI design will be kept very simple. Tools that will be used are Github API, Langchain, OpenAI Embeddings and Upstash Vector. Github repo of the project is here, also you can deploy the project to your Vercel account using the button on the Readme file of the project.
Get Started
Create a Next.js Application
To create a new project, first navigate to the directory that you want to create your project in using your terminal. Then, run the following commands:
npm install -g create-next-app
npx create-next-app@latestnpm install -g create-next-app
npx create-next-app@latestWhen prompted choose a name for your project and pick Yes for the options:
- Use Tailwind CSS (for UI design)
- Use "App Router"
After this step, go to your project's folder with the cd command and install the necessary libraries
npm install @octokit/core
npm install -S langchain
npm install -S @upstash/vectornpm install @octokit/core
npm install -S langchain
npm install -S @upstash/vectorFrom now on, when you are at the directory of your project the command
npm run devnpm run devis going to be sufficient to run the project on localhost:3000.
If you need further clarification, you can refer to the Readme or the Next.js documentation
Set up Upstash Vector
Navigate to Upstash Console and create an account if you don't have already. Then, login to your account and go to Vector using the bar at the top of the page. After that click Create Index.
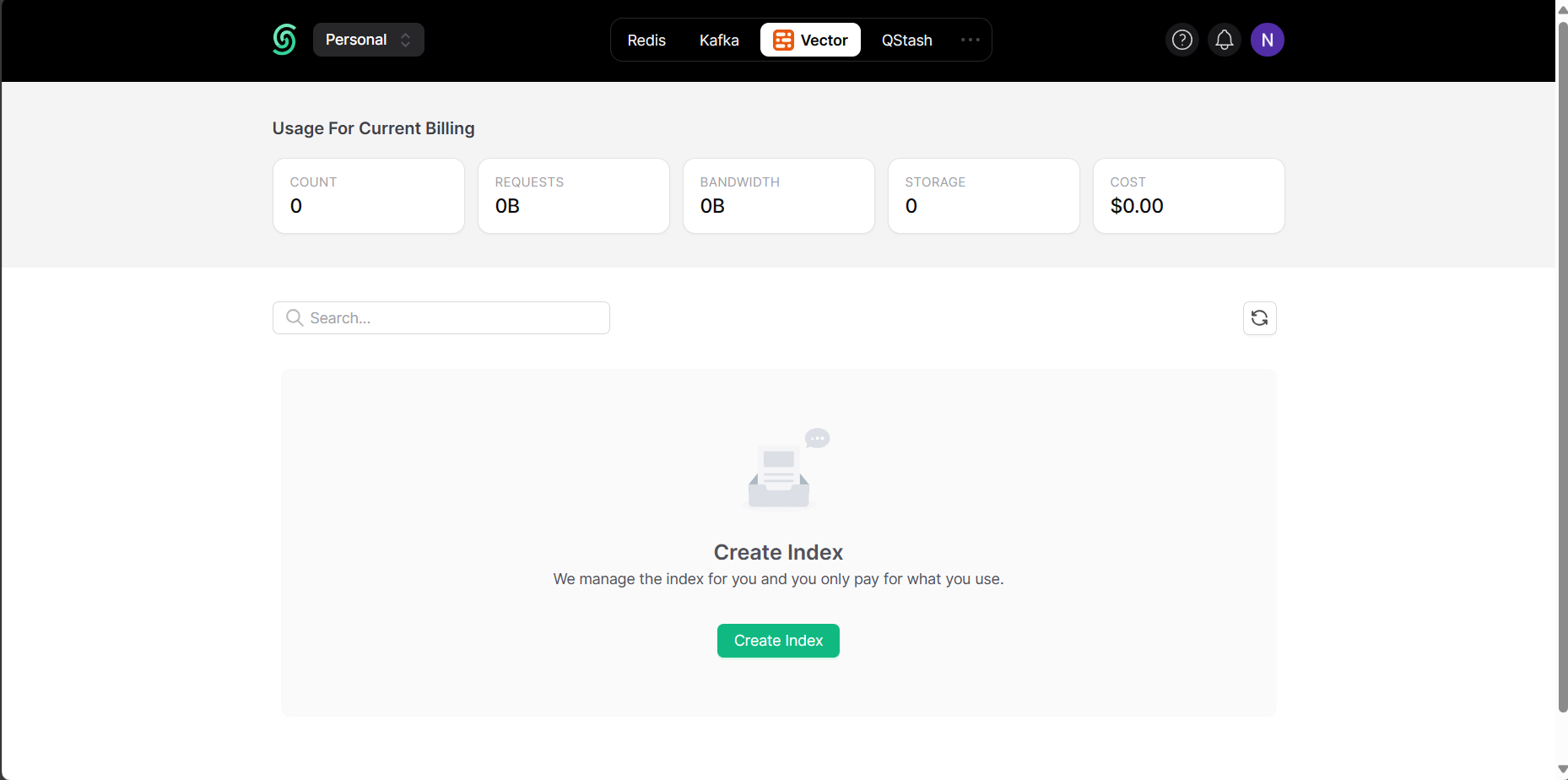
Then pick a name for your database as you like and choose the appropriate options for your region and embedding model. Since we are using OpenAI's text-embedding-3-small embedding model in this tutorial, we picked 1536 as dimension and COSINE as metric. If you are using any other model, you have to check the documentation see which values you have to choose.
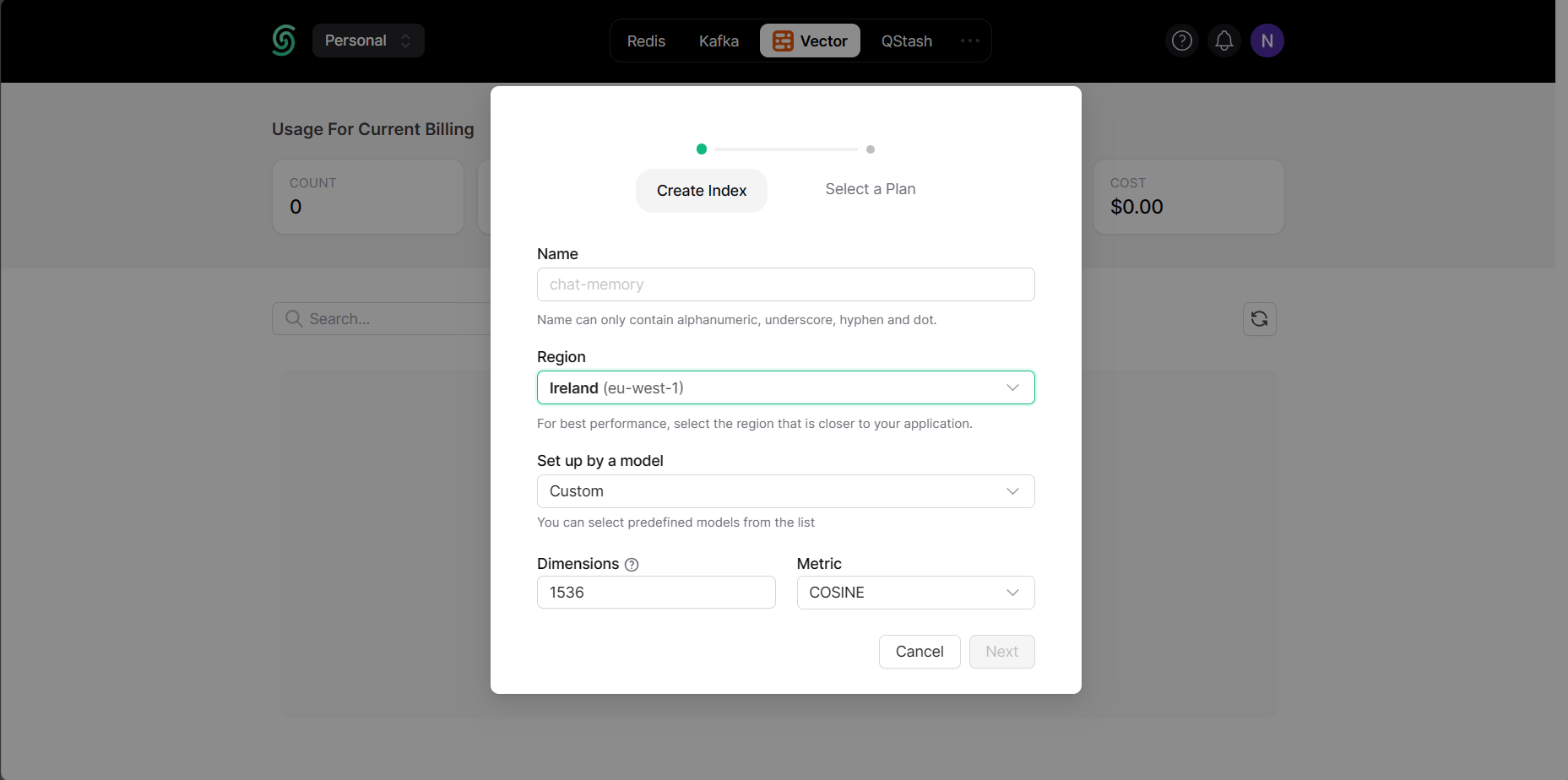
Then pick your plan as you like and click Create.
Just like that, your database is ready to use.
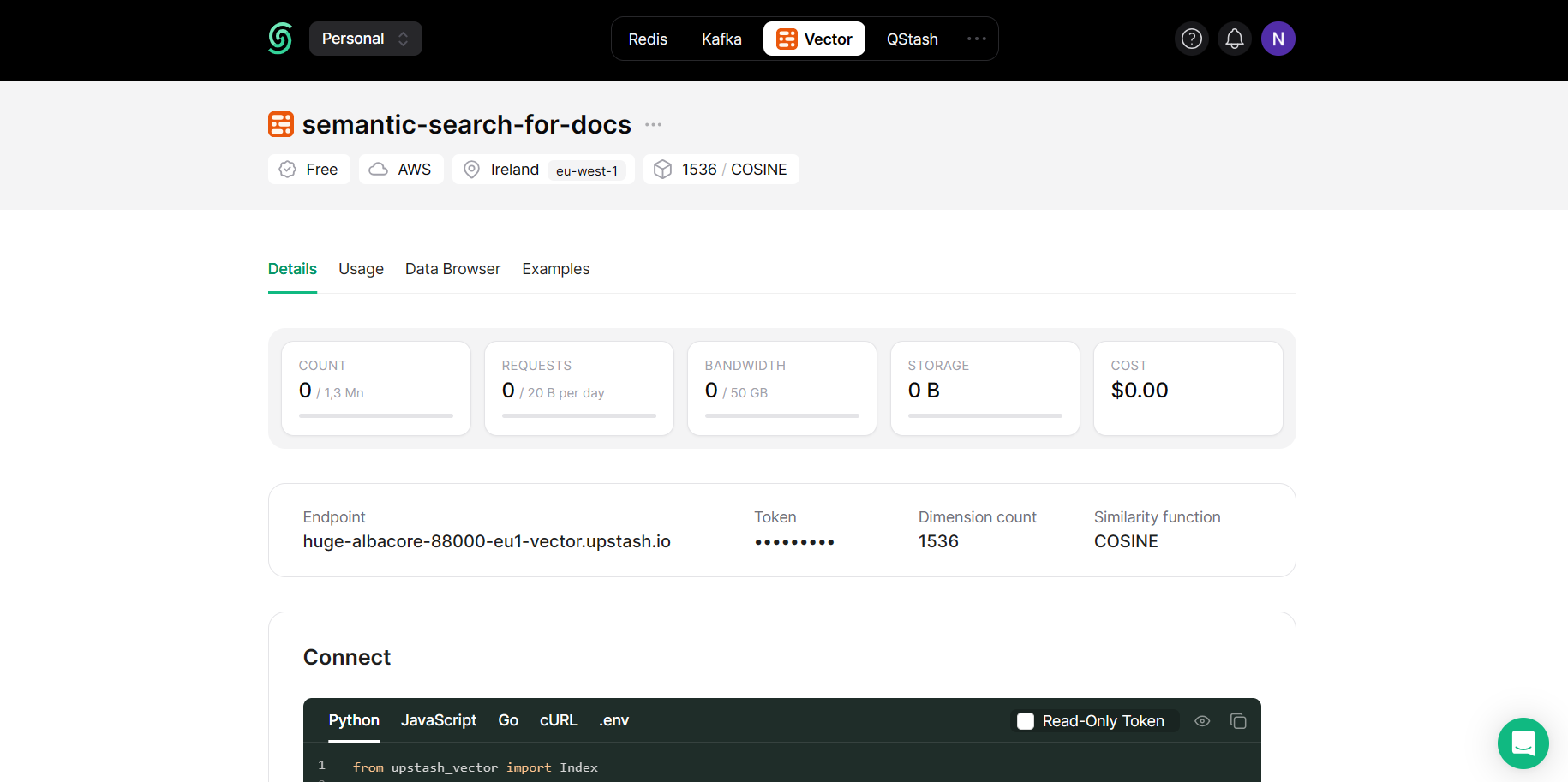
Create the environment variables
Now create a file called .env in your project and add it to the .gitignore file if you are considering to add this project to your Github account. In this file, we will store our API keys. To get your Upstash Vector keys go to the database you created, switch to the tab Details and copy the content under .env tab as in the image.
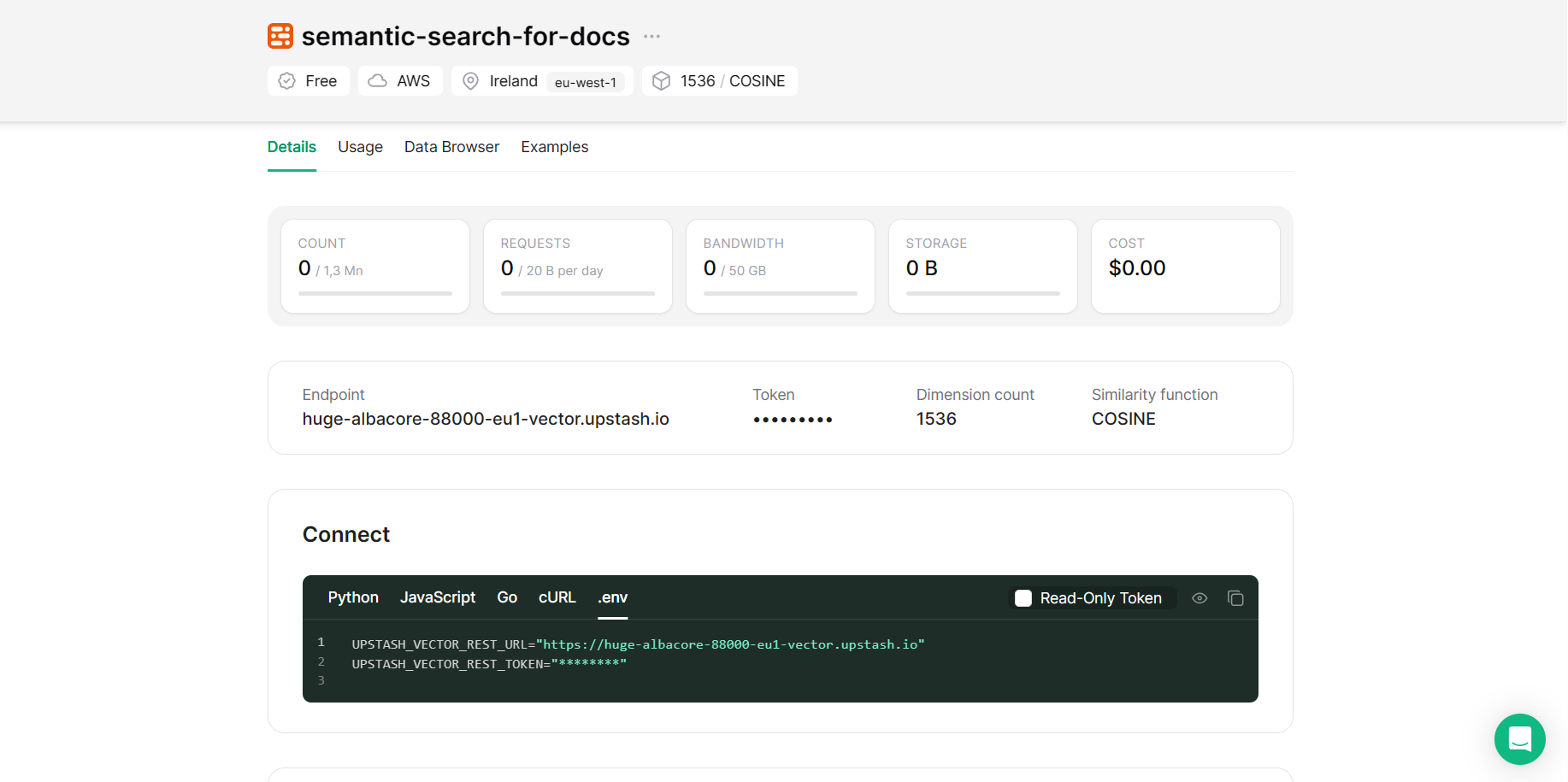
You also need an OpenAI API key for the project. Once you add it too, your .env file should look like this
UPSTASH_VECTOR_REST_URL="..."
UPSTASH_VECTOR_REST_TOKEN="..."
OPENAI_API_KEY="..."UPSTASH_VECTOR_REST_URL="..."
UPSTASH_VECTOR_REST_TOKEN="..."
OPENAI_API_KEY="..."Now, you ready to start the implementation.
Implementation
Most of our code will be under the app directory since we initiated the Next.js project with app router.
We need to implement these 3 features to complete the project:
- Read the repository and create chunks (
app/components/ParseRepo.jsx) - Create an API endpoint that upserts the documents to Upstash Vector (
app/api/addDocuments/route.js) - Create an API endpoint that searches queries (
app/api/search/route.js)
Create the User Interface
First, we need to take the owner name and repo name of the target repository from the user. So, we need two forms and one submit button. These two forms have to assign their values to some variables, therefore we need to use the useState function. We also want to disable the submit button when a submit is getting processed. This job is dependent on user input too. So, we need to use useState again.
We also have to specify what our program has to do when the user gives input. So, we have to implement handleInputChange and handleSubmit functions. These functions will update the values of our two important variables. handleSubmit will also send the input to our parser script which will be implemented shortly.
Code below is our implementation that covers all these properties.
"use client";
import { useState } from "react";
import { parseMarkdowns } from "@/components/ParseRepo";
const Home = () => {
// create variables that will be set based on the input
const [submitting, setSubmitting] = useState(false);
const [inputText, setInputText] = useState({ owner: "", repo: "" });
const handleInputChange = (e) => {
const { name, value } = e.target;
setInputText((prevState) => ({
...prevState,
[name]: value,
}));
};
// when the input is submitted run the parser script
const handleSubmit = async (e) => {
e.preventDefault();
setSubmitting(true);
const res = await parseMarkdowns(inputText.owner, inputText.repo);
setSubmitting(false);
};
return (
<div>
<form onSubmit={handleSubmit}>
<label>
<span>Owner: </span>
<input
type="text"
name="owner"
value={inputText.owner}
onChange={handleInputChange}
placeholder="Owner name"
required
/>
</label>
</form>
<form onSubmit={handleSubmit}>
<label>
<span>Repo: </span>
<input
type="text"
name="repo"
value={inputText.repo}
onChange={handleInputChange}
placeholder="Repo name"
required
/>
</label>
<button type="submit" disabled={submitting}>
{submitting ? "Submitting..." : "Submit"}
</button>
<div>
{submitting && (
<div>
You submitted: {inputText.owner} / {inputText.repo}
</div>
)}
</div>
</form>
</div>
);
};
export default Home;"use client";
import { useState } from "react";
import { parseMarkdowns } from "@/components/ParseRepo";
const Home = () => {
// create variables that will be set based on the input
const [submitting, setSubmitting] = useState(false);
const [inputText, setInputText] = useState({ owner: "", repo: "" });
const handleInputChange = (e) => {
const { name, value } = e.target;
setInputText((prevState) => ({
...prevState,
[name]: value,
}));
};
// when the input is submitted run the parser script
const handleSubmit = async (e) => {
e.preventDefault();
setSubmitting(true);
const res = await parseMarkdowns(inputText.owner, inputText.repo);
setSubmitting(false);
};
return (
<div>
<form onSubmit={handleSubmit}>
<label>
<span>Owner: </span>
<input
type="text"
name="owner"
value={inputText.owner}
onChange={handleInputChange}
placeholder="Owner name"
required
/>
</label>
</form>
<form onSubmit={handleSubmit}>
<label>
<span>Repo: </span>
<input
type="text"
name="repo"
value={inputText.repo}
onChange={handleInputChange}
placeholder="Repo name"
required
/>
</label>
<button type="submit" disabled={submitting}>
{submitting ? "Submitting..." : "Submit"}
</button>
<div>
{submitting && (
<div>
You submitted: {inputText.owner} / {inputText.repo}
</div>
)}
</div>
</form>
</div>
);
};
export default Home;The code above returns thThe code above generates the user interface, but it is not displayed to the user yet. This is because, in Next.js, the layout.jsx file controls what is presented to the user. Therefore, we also need to create and implement this file. Additionally, we should include the metadata for our web application in that file.
We will create the file in a way that it creates a very simple layout for its children component. (one page in our case) This approach is very useful while creating dynamic pages.
export const metadata = {
title: "semantic search engine for docs",
description: "semantic search engine for docs",
};
const RootLayout = ({ children }) => {
return (
<html lang="en">
<body>
<div className="main"></div>
<main className="app">{children}</main>
</body>
</html>
);
};
export default RootLayout;export const metadata = {
title: "semantic search engine for docs",
description: "semantic search engine for docs",
};
const RootLayout = ({ children }) => {
return (
<html lang="en">
<body>
<div className="main"></div>
<main className="app">{children}</main>
</body>
</html>
);
};
export default RootLayout;Parse The Repo
This part is about creating the parseMarkdown function which was referred in the first part as the parser script. More specifically, we will implement the following flow:
- Access the repo
- Extract the files with extenisons
.mdor.mdx - Create smaller chunks from the files
POSTthe chunks to API
To access the repo we need to use the Github API and to create the chunks we need several libraries from Langchain. Let's start by adding these imports and creating the objects
import { Octokit } from "@octokit/core";
import { Document } from "langchain/document";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
const octokit = new Octokit(); // Github API client
const splitter = RecursiveCharacterTextSplitter.fromLanguage("markdown", {
chunkSize: 500, // You can change this according to your needs
chunkOverlap: 0, // You can change this according to your needs
});
const parseMarkdowns = async (owner, repo, path = "") => {
// we will fill this part in this section
};
export { parseMarkdowns };import { Octokit } from "@octokit/core";
import { Document } from "langchain/document";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
const octokit = new Octokit(); // Github API client
const splitter = RecursiveCharacterTextSplitter.fromLanguage("markdown", {
chunkSize: 500, // You can change this according to your needs
chunkOverlap: 0, // You can change this according to your needs
});
const parseMarkdowns = async (owner, repo, path = "") => {
// we will fill this part in this section
};
export { parseMarkdowns };While implementing the parseMarkdown function, we will follow a recursive approach. Each call of the function will handle a different directory. The function will hold the two lists which hold the markdown files and directories that are located in the current directory.
Markdown files will be read using the Github API and then they will be converted to Document objects from Langchain library. Converting the files to document enables us to add metadata to them. Thanks to that, while searching we won't have to look for the resulting query in the files again, we can immediately return the file name too.
Then, we have to implement a for loop that calls the parseMarkdown for each directory we have found. So, we reach not only the markdowns that are in the master directory, but the ones that take place under the subdirectories.
Finally, we split the documents we have just created using Langchain's document splitter and create a POST request that sends the output of this function to our endpoint which we are going to create after this section. This part will also be called in every recursive call in order to lower the number of documents posted in one call.
try {
// Access the directory using GitHub API
const response = await octokit.request('GET /repos/{owner}/{repo}/contents/{path}', {
owner,
repo,
path,
});
const files = response.data;
// Filter out the Markdown files
const markdowns = files.filter(file => {
return file.type === 'file' && (file.name.endsWith('.md') || file.name.endsWith('.mdx'));
});
// Filter out the directories
const directories = files.filter(file => file.type === 'dir');
// Get the contents of the Markdown files
const contents = await Promise.all(markdowns.map(async (file) => {
const fileResponse = await octokit.request('GET /repos/{owner}/{repo}/contents/{path}', {
owner,
repo,
path: file.path,
});
// Decode the content from base64
const content = Buffer.from(fileResponse.data.content, 'base64').toString('utf-8');
// Create a Document object using the content from the Markdown file
const document = new Document({ metadata: {name: file.path}, pageContent: content });
return document;
}));
// Recursively search subdirectories for Markdown files
for (const directory of directories) {
await parseMarkdowns(owner, repo, directory.path);
}
// Split the documents into chunks and post them to the api
let output = [];
output = await splitter.splitDocuments(contents);
try {
const response = await fetch('/api/addDocument', {
method: 'POST',
body: JSON.stringify(output),
});
return JSON.stringify(response);
} catch (error) {
console.error("Error in POST:", error);
return output;
}
} catch (error) {
console.error("Error in GET:", error);
return [];
}
try {
// Access the directory using GitHub API
const response = await octokit.request('GET /repos/{owner}/{repo}/contents/{path}', {
owner,
repo,
path,
});
const files = response.data;
// Filter out the Markdown files
const markdowns = files.filter(file => {
return file.type === 'file' && (file.name.endsWith('.md') || file.name.endsWith('.mdx'));
});
// Filter out the directories
const directories = files.filter(file => file.type === 'dir');
// Get the contents of the Markdown files
const contents = await Promise.all(markdowns.map(async (file) => {
const fileResponse = await octokit.request('GET /repos/{owner}/{repo}/contents/{path}', {
owner,
repo,
path: file.path,
});
// Decode the content from base64
const content = Buffer.from(fileResponse.data.content, 'base64').toString('utf-8');
// Create a Document object using the content from the Markdown file
const document = new Document({ metadata: {name: file.path}, pageContent: content });
return document;
}));
// Recursively search subdirectories for Markdown files
for (const directory of directories) {
await parseMarkdowns(owner, repo, directory.path);
}
// Split the documents into chunks and post them to the api
let output = [];
output = await splitter.splitDocuments(contents);
try {
const response = await fetch('/api/addDocument', {
method: 'POST',
body: JSON.stringify(output),
});
return JSON.stringify(response);
} catch (error) {
console.error("Error in POST:", error);
return output;
}
} catch (error) {
console.error("Error in GET:", error);
return [];
}
Add Documents to Upstash Vector
In this step, we will start to create the first API endpoint, that upserts the chunks we have just created to our Upstash Vector database. To complete this task, what we have to do is the following:
- Receive the
POSTrequest - Create the index
- Create the embeddings
- Create the Upstash Vector store object
- Add the embeddings to database
- Return response
To create the endpoint, we have to create a folder called api and create a folder that names our endpoint inside. In our case this folder's name will be addDocuments. For implementation of endpoints Next.js requires the file's name to be route.js.( .js part can change according to language.)
To start our implementation, we have to specify the necessary libraries and create a function that handles the POST request and it should look like this. Also, we have to receive the message that was sent from the frontend. We can add the successful and unsuccesful responses too.
import { UpstashVectorStore } from "@langchain/community/vectorstores/upstash";
import { OpenAIEmbeddings } from "@langchain/openai";
import { Index } from "@upstash/vector";
export async function POST(req) {
// Get the data from the request
const data = await req.json();
try {
// we will fill this part in this section
return new Response(JSON.stringify("Successful"), {
headers: { "Content-Type": "application/json" },
status: 200,
});
} catch (error) {
return new Response(JSON.stringify({ error: error.message }), {
headers: { "Content-Type": "application/json" },
status: 500,
});
}
}import { UpstashVectorStore } from "@langchain/community/vectorstores/upstash";
import { OpenAIEmbeddings } from "@langchain/openai";
import { Index } from "@upstash/vector";
export async function POST(req) {
// Get the data from the request
const data = await req.json();
try {
// we will fill this part in this section
return new Response(JSON.stringify("Successful"), {
headers: { "Content-Type": "application/json" },
status: 200,
});
} catch (error) {
return new Response(JSON.stringify({ error: error.message }), {
headers: { "Content-Type": "application/json" },
status: 500,
});
}
}Now, we have to create our Upstash Vector Index object and OpenAI Embeddings objects. To create the OpenAI Embeddings we will use the library from Langchain. These objects require our API keys as arguments. We have added them to environment variables before, so we can specify them like below. Also, to use OpenAI Embeddings, we have to specify an embedding model. Previously, we have mentioned that we will use the text-embedding-3-small model, so we add it too.
// Create an Index object
const index = new Index({
url: process.env.UPSTASH_VECTOR_REST_URL,
token: process.env.UPSTASH_VECTOR_REST_TOKEN,
});
// Create an OpenAIEmbeddings object
const embeddings = new OpenAIEmbeddings({
openAIApiKey: process.env.OPENAI_API_KEY,
modelName: "text-embedding-3-small",
});// Create an Index object
const index = new Index({
url: process.env.UPSTASH_VECTOR_REST_URL,
token: process.env.UPSTASH_VECTOR_REST_TOKEN,
});
// Create an OpenAIEmbeddings object
const embeddings = new OpenAIEmbeddings({
openAIApiKey: process.env.OPENAI_API_KEY,
modelName: "text-embedding-3-small",
});We have created the necessary objects, now we have to create the embeddings and add them to our database. To do this, we will use the UpstashVectorStore object from Langchain.
// Create a VectorStore object
const vectorStore = new UpstashVectorStore(embeddings, { index });
// Add the documents to the VectorStore
await vectorStore.addDocuments(data);// Create a VectorStore object
const vectorStore = new UpstashVectorStore(embeddings, { index });
// Add the documents to the VectorStore
await vectorStore.addDocuments(data);From now on, when a user submits an input, it will be parsed and upserted to the vector database. If you like, you can check whether the operation is successful or not from the Logs tab in Vercel or you can simply go to your relevant vector database on Upstash Console and check the Data Browser tab. Your documents will be visible there if the upsert is successful.
Search Queries
Finally, we have to create the enpoint for searching. This time, we will create a folder called search under api and create the route.js file again.
In this endpoint, we will handle GET request because search will receive its queries from the URL. For example if the project is running on local http://localhost:3000/api/search?query=computer will search the query computer. (In this example the prompt variable we will declare in this section is assigned to the string query.)
Things we have implement in this part are as follows:
- Receive query from URL
- Create the index, embedding and vector store objects
- Search the query
- Return responses
Just like the previous part, we will start the implementation by specifying the imports and responses. This time we will also create the URL object and initialize the necessary variables.
import { UpstashVectorStore } from "@langchain/community/vectorstores/upstash";
import { OpenAIEmbeddings } from "@langchain/openai";
import { Index } from "@upstash/vector";
export async function GET(req) {
// Parse the query from the URL
const url = new URL(req.url);
// Number of results
const topK = 3;
const prompt = "query";
try {
// we will fill this part in this section
return new Response(response, {
headers: { "Content-Type": "application/json" },
status: 200,
});
} catch (error) {
return new Response(JSON.stringify({ error: error.message }), {
headers: { "Content-Type": "application/json" },
status: 500,
});
}
}import { UpstashVectorStore } from "@langchain/community/vectorstores/upstash";
import { OpenAIEmbeddings } from "@langchain/openai";
import { Index } from "@upstash/vector";
export async function GET(req) {
// Parse the query from the URL
const url = new URL(req.url);
// Number of results
const topK = 3;
const prompt = "query";
try {
// we will fill this part in this section
return new Response(response, {
headers: { "Content-Type": "application/json" },
status: 200,
});
} catch (error) {
return new Response(JSON.stringify({ error: error.message }), {
headers: { "Content-Type": "application/json" },
status: 500,
});
}
}We have to read the input using the URL object, in order to read the input we have to create a URLSearchParams object and get the input with it.
// Get the query from the URL
const searchParam = new URLSearchParams(url.searchParams);
const query = searchParam.get(prompt);// Get the query from the URL
const searchParam = new URLSearchParams(url.searchParams);
const query = searchParam.get(prompt);Recall that we have created index, embeddings and vector store objects in addDocuments. We have to create them here too in order to be able to reach our database and embed the query.
// Create a new Index object
const index = new Index({
url: process.env.UPSTASH_VECTOR_REST_URL,
token: process.env.UPSTASH_VECTOR_REST_TOKEN,
});
// Create a new OpenAIEmbeddings object
const embeddings = new OpenAIEmbeddings({
openAIApiKey: process.env.OPENAI_API_KEY,
modelName: "text-embedding-3-small",
});
// Create a new UpstashVectorStore object
const vectorStore = new UpstashVectorStore(embeddings, { index });// Create a new Index object
const index = new Index({
url: process.env.UPSTASH_VECTOR_REST_URL,
token: process.env.UPSTASH_VECTOR_REST_TOKEN,
});
// Create a new OpenAIEmbeddings object
const embeddings = new OpenAIEmbeddings({
openAIApiKey: process.env.OPENAI_API_KEY,
modelName: "text-embedding-3-small",
});
// Create a new UpstashVectorStore object
const vectorStore = new UpstashVectorStore(embeddings, { index });Now, we are ready to search the query. The topK variable we have specified at the beginning helps us here. Since we have defined it as 3, we will see the best 3 results. You can choose it as you like.
// Perform a similarity search with the query
const result = await vectorStore.similaritySearchWithScore(query, topK);// Perform a similarity search with the query
const result = await vectorStore.similaritySearchWithScore(query, topK);Finally, we have to create the response to able to return our results to the user. Creating a 2-dimensional array and keeping the content and page names each of these arrays would be a simple and useful approach here.
let response = [];
result.forEach((element) => {
const res_one = [element[0].pageContent, element[0].metadata.name, "\n\n\n"];
response.push(res_one);
});let response = [];
result.forEach((element) => {
const res_one = [element[0].pageContent, element[0].metadata.name, "\n\n\n"];
response.push(res_one);
});With that, we've finalized the implementation.
Conclusion
In this blog, we developed a simple program that can create semantic search engines for any docs repository on Github using Upstash Vector database. If you'd like to learn more about Upstash, you can visit other blog posts. Also, if you have any questions or face any issues feel free to contact me from the project's repository or my Linkedin account.